Chinese Generation Evaluation
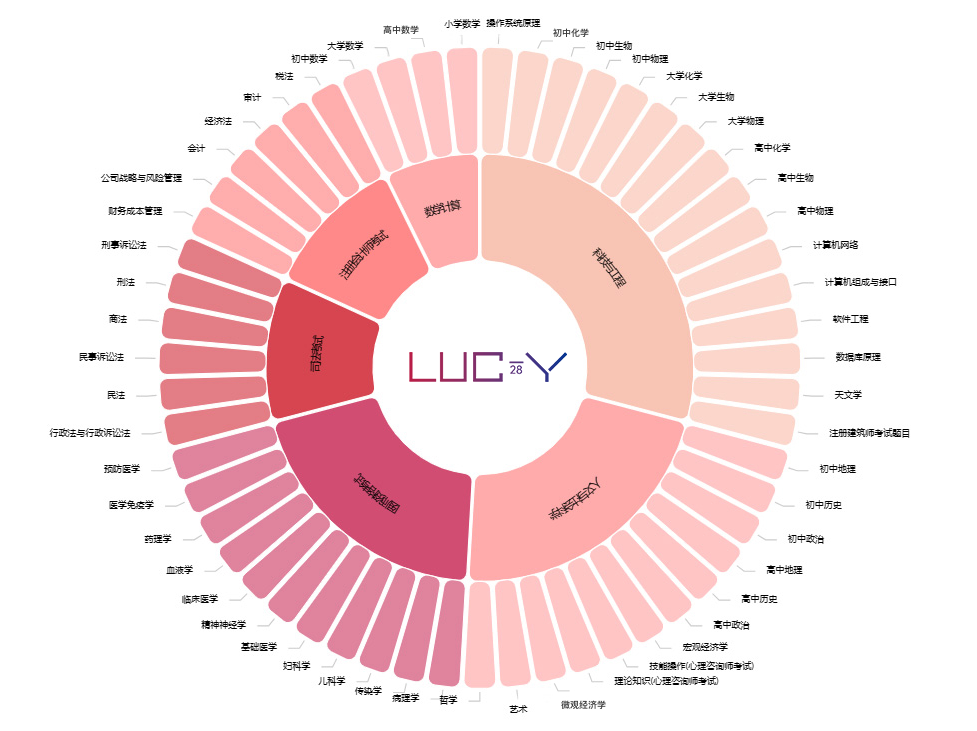
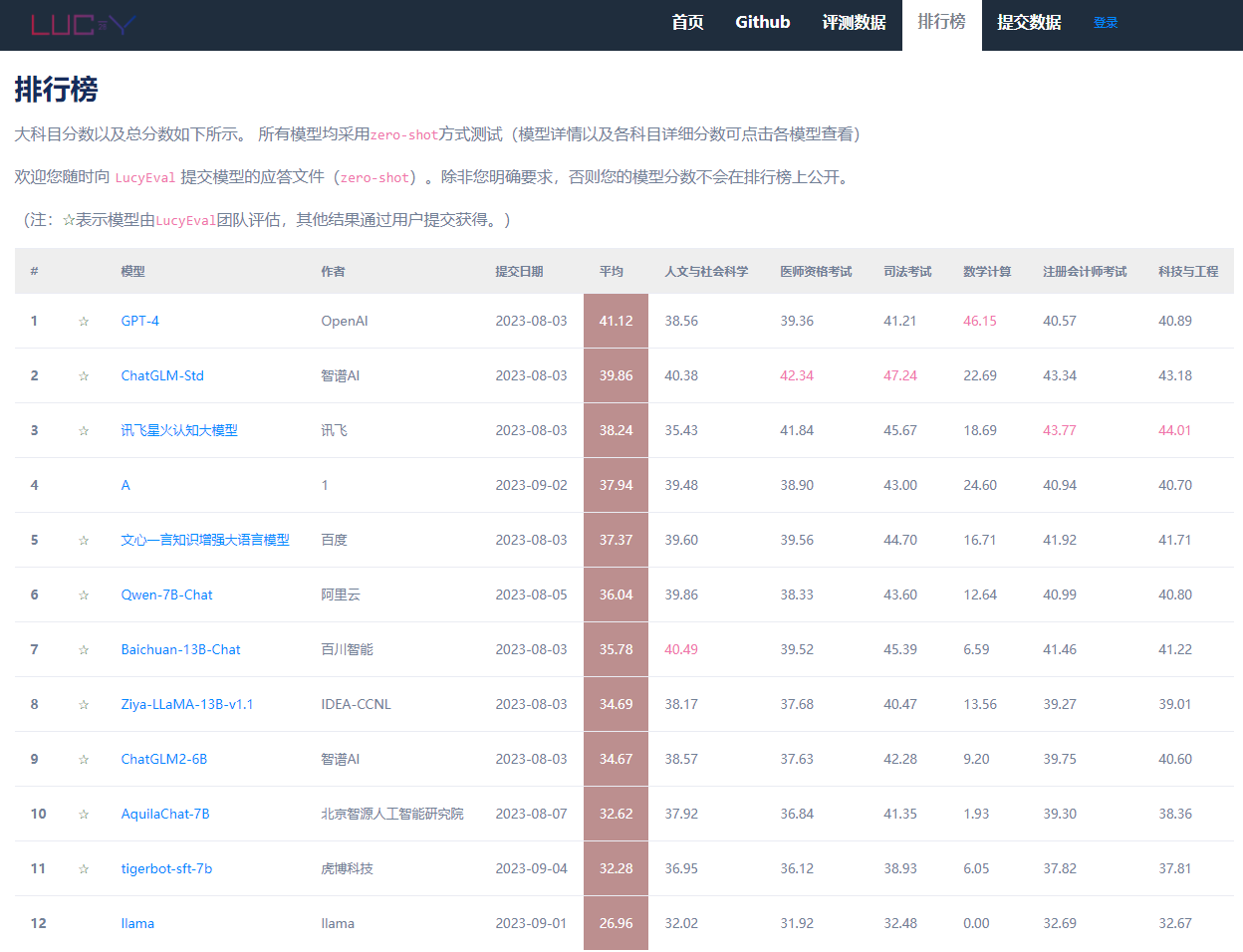
LucyEval 是甲骨易AI研究院与LanguageX AI Lab联合推出的中文大模型全面评测体系(包括理解能力、生成能力、安全与价值观、幻觉等等)。其中的CG-Eval是针对中文大模型生成能力的测试基准。在CG-Eval测试中,受测的中文大语言模型需要对科技与工程、人文与社会科学、数学计算、医师资格考试、司法考试、注册会计师考试这六个大科目类别下的55个子科目的11000道不同类型问题做出准确且相关的回答。 我们设计了一套复合的打分系统,对于非计算题,每一道名词解释题和简答题都有标准参考答案,采用多个标准打分然后加权求和。对于计算题目,我们会提取最终计算结果和解题过程,然后综合打分。
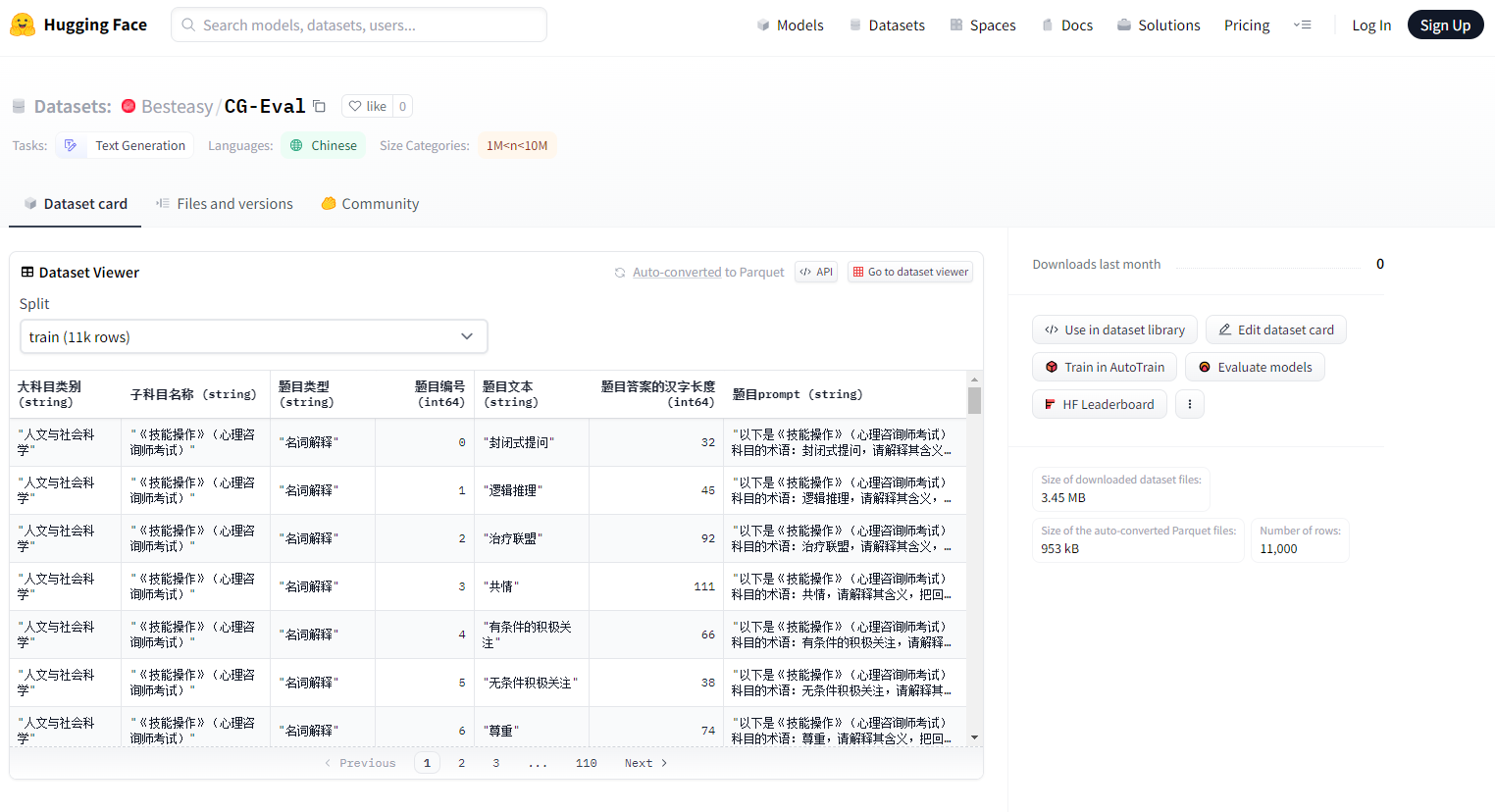
下载数据集后,请使用“题目prompt”列对应的提示词向模型提问,并在csv文件中增加“回答”列,存放模型的回复。
请注意题目的回答要与提示词、问题编号、科目名称对应。
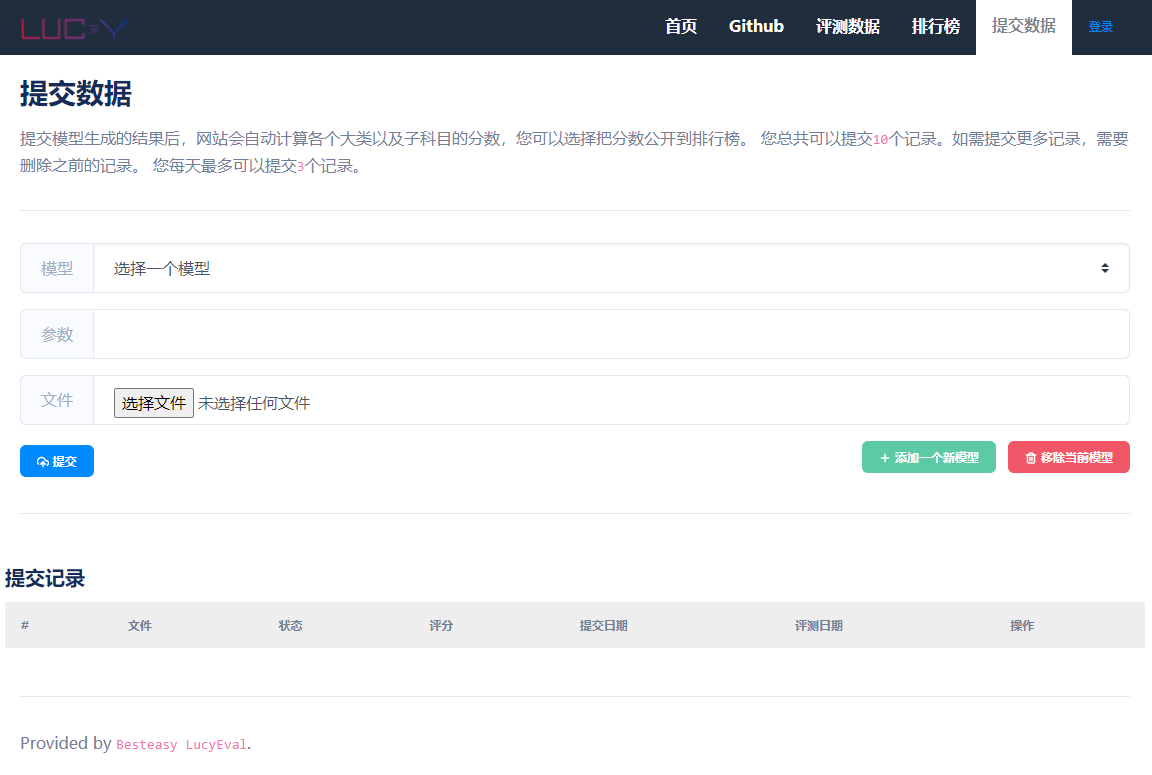
在收集到所有回答后,请点击“提交数据”将csv文件提交以便自动评测。
您需要提交的csv文件应具有以下字段:大科目类别、子科目名称、题目类型、题目编号、题目文本、题目答案的汉字长度、题目prompt、回答。
如果本评测对您的研发或学术工作有所帮助,请引用我们的文章:
√ 已复制到粘贴板
@misc{zeng2023evaluating,
title={Evaluating the Generation Capabilities of Large Chinese Language Models},
author={Hui Zeng and Jingyuan Xue and Meng Hao and Chen Sun and Bin Ning and Na Zhang},
year={2023},
eprint={2308.04823},
archivePrefix={arXiv},
primaryClass={cs.CL}
}